Understanding your data
As we collect and organize our assessment data, we will have at our disposal many documents, tables and graphs that are packed full of numbers. We may be tempted to start adding, subtracting, multiplying and dividing these numbers at will as we proceed in answering assessment questions like the following:
- Is Billy making growth with respect to his reading fluency skills?
- Has Jane closed the gap in math problem solving skills compared to her peers?
- Are our 4th grade students meeting state trajectories in reading?
- How much growth is necessary for Jill to become proficient in reading next year?
- Has the newly implemented instructional strategies in writing made a difference with our middle school students’ writing skills?
This temptation may be fostered by the experiences that we have with numbers in the past and our knowledge of mathematical computation. Despite this fact, please understand that when dealing with assessment data, not all numbers are created the same, and thus, not all mathematical operations are applicable to each and every number.
Whether our data are considered to be Nominal, Ordinal, Interval or Ratio, we must have a solid understanding of the benefits and limitations of the different types of data so that we can make more accurate and appropriate judgments about students and their performance in comparison to identified achievement targets. For a review of the four types of data and the “permitted” mathematical computations of each type, please read Four Types of Data.
Different types of scoring
Raw scores (ratio data)
Simply put, raw scores are the total correct responses given on an assessment, typically one that is either standardized or norm-referenced. All other scores are derived from raw scores.
Example:
Every Friday Mrs. Schmitz, a third grade teacher, gives her students a spelling assessment. Once the students have completed the assessment, Mrs. Schmitz scores them and calculates the total number of correct words each student received.
This total can also be referred to as the student’s raw score.
Percent correct (ratio data)
Percent correct is a percentage representing how well students did on an assessment out of 100 percent. This number is obtained by dividing the total number of points earned by the total number of points possible and then multiplying by 100.
Example:
Mrs. Schmitz may want to provide her students with their percent correct score in addition to their raw score for the weekly spelling assessment.
To practice calculating the percent correct for one of Mrs. Schmitz student’s spelling assessment:
- Jimmy’s Raw Score: 15
- Points Possible: 25
- 15/25 = .6
- .6×100 = 60% (Percent Correct Score)
Percentile ranks (ordinal data)
- Percentile ranks are scores that tell what percentage of same-grade peers scored equal to or greater than the tested individual on a norm-referenced or standardized assessment.
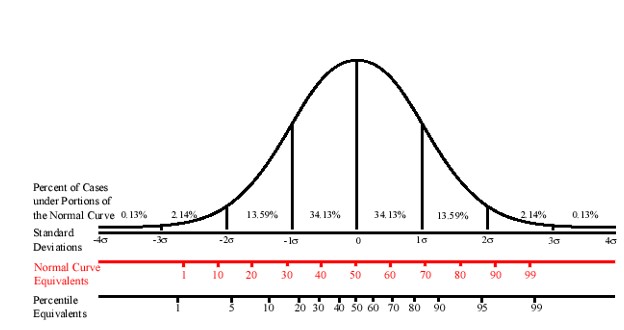
- Percentile ranks can be used to compare a student’s achievements to other same-grade peers and ranks range from 1 to 99. Generally speaking, students obtaining percentile rank scores between the 16th and the 84th percentile rank would be considered in the average range of functioning (ie: within one standard deviation of the median or 50th percentile rank).
- Percentile ranks are often referred to as status scores.
- Although percentile rank scores are useful for some types of decision making, its psychometric properties limit their usefulness for some data analysis. The primary difficulty is that all points along the percentile distribution do not represent equal units.
- Raw score differences between percentile ranks are smaller near the mean (50th percentile rank) than at the extremes of the distributions (ie: 10th or 90th percentile rank).
- There are two forms of percentile ranks:
National Percentile Rank. The national percentile rank are scores that reflect what percentage of same-grade peers from a nation-wide sample scored equal to or less then the individual tested.
State Percentile Rank serves the same purpose; however, the score is based on same-aged peers from the same state.
Example:
Let’s say that John received a percentile rank of 74 on the Reading portion of the Iowa Assessments. That means that John scored equal to or greater than 74% of same-grade peers from the standardized sample. This also means that 26% of John’s same-aged peers scored higher than he scored.
Standard scores (interval/ratio data)
Standard scores are used to tell how far above or below the mean an individual’s score lies. This is accomplished by converting the individual’s raw score to a number on a common scale typically with an average of 100 and a standard deviation of 15. The standard score allows for comparisons to be made across age or grades. They are the most powerful scores statistically and are derived from the properties of the normal probability curve; thus, preserving the absolute differences between scores, a feature percentile scores do not possess.
Standard scores are:
- equal interval scores
- often age/grade independent
- often referred to as growth scores
Typical scores in this category include:
- IQ scores
- National Standard Scores (NSS) on the Iowa Assessments
- RIT scores and other such scaled scores
There are two main types of standard scores: National Standard Scores and State Standard Scores. National Standard Scores are based on the national average and State Standard Scores are based on the states average. Typically, it is recommended to use National Standard Scores.
Example:
Molly’s parents were worried about her performance in school so they asked for a special education eligibility evaluation to be conducted. As part of the evaluation, an intelligence test was administered. Molly’s overall standard score for IQ was 85. This score indicates that Molly scored 15 points below the average IQ.
Other large scale assessments, such as the Iowa Assessments, also have standard scores. Again, these scores can be either national standards scores or local (Iowa standard scores). Either way these standard scores are used to measure student achievement and growth, much like the Rasch Unit Scores (or RIT scores), but with slightly different ranges of scores across grades.
Example:
Molly may have taken the Iowa Assessments in the fall of 3rd grade and received a 160. According to the average national standard score for the Iowa Assessments, Molly’s score would fall 16 points below the average.
RIT score or rasch unit
- The Rasch Unit score is also used to measure student achievement and growth. The Rasch Unit score serves the same function as a standard score. The scores can be added together to calculate accurate class or school averages.
- RIT scores range from about 150 to 300. Students typically start at the 150-190 level in the third grade and progress to the 240-300 level by high school. RIT scores make it possible to follow a student’s educational growth from year to year.
- For more information on RIT scores, view the Northwest Evaluation Association link: Measures of Academic Progress
Normal curve equivalents or NCE
Normal Curve Equivalents or NCEs are Ratio Data
Normal curve equivalents (NCEs) are a comparatively new normative measure developed as a uniform reporting method for Title I programs focusing on student improvement and growth. Although normal curve equivalents resemble percentile ranks in various ways, there are also fundamental differences which provide NCEs with certain distinct advantages in this type of research setting.
NCEs are represented on a scale of 0 – 100. This scale coincides with the national percentile scale at 1, 50, and 99. NCEs have the advantage of being based on an equal-interval scale. That is, the difference between two successive scores on the scale is the same over all parts of the scale. This means that, unlike percentiles, you can average NCE scores to compare groups of students.
You can also convert average NCEs to national percentiles ranks (NPRs) for a more meaningful understanding of the scores. This is because NCEs and NPRs have a consistent relationship. Using normal curve equivalents allows for educators to compare results across different assessments.
Example:
Jenny received a normal curve equivalent score of 45 on the math subtest and a score of 65 on the reading subtest. Due to the properties associated with the normal curve equivalent scores, we can say that Jenny scored 20 points higher on the reading subtest than on the math subtest.
Z scores and T scores
Z Scores
A Z-score (also known as a z value, standard score, and normal score) is used to describe a particular score in terms of where it fits into an overall group of scores. In other words, a Z score is an ordinary score transformed so that it better describes the location of that score in a distribution. A Z-score has a mean of zero and a standard deviation of one.
T Scores
T scores are used to tell individuals how far their score is from the mean. T scores have a mean of 50 and a standard deviation of 10. Therefore, if a student’s raw score was converted to a T-score and their T-score was 70 it would in turn mean that their score was 20 points above the mean. One advantage of using a T-score over a Z-score is that T scores are relatively easy to explain to parents when reporting the student’s assessment scores.
Disaggregation of data
Disaggregated data
IIs data that is separated into specific subgroups of students. Disaggregated data uncovers important information about patterns and trends that could be missed when just looking at a data set.
Disaggregated data tells us…
- If there is a pattern within the data between subgroups of students
- If specific groups of students are performing at a higher rate than other groups of students
- If there is a common trend in the data
- Examples of Subgroups
- Gender
- Socio-Economic Status
- Race and Ethnicity
- English as Second Language
Data management tools
There are several different programs that can be used to assist in the data collection and analyses processes. Some of the more popular options available for professionals are:
EdInsight
EdInsight is the Iowa Department of Education’s statewide longitudinal data system. The goal of this system is to provide Iowa educators the tools for deep and efficient data analysis in a number of important student performance areas. With this data in hand, Iowa educators are empowered to help all students achieve greater success.
EdInsight can be accessed by Iowa educators through Iowa’s educational portal. This access requires approval through your district’s or AEA’s security officer.
More information about EdInsight can be found on the Iowa Department of Education website
Data Definitions
Nominal data or categorical
This type of data has no numerical properties and cannot be placed in any order:
- The nominal or categorical scale is data in which the information collected has no numerical properties.
- Nominal data represents specific independent categories that cannot be placed in any order.
- Examples include:
- Gender
- Proficient
- Non-proficient
- Grade
- Ethnicity
- Native language
- For nominal data, Bar Graphs, Pie Graphs, and Line Graphs are the best way to represent your data, these graphs will be demonstrating the frequency of each category.
Ordinal data
Data that are put into categories and then ranked are called ordinal data:
- In the ordinal scale, information is placed in categories and then ranked along a continuum.
- There is no zero or equal unit size.
- Examples include:
- Percentile Rank (PR)
- National Percentile Rank (NPR)
- Iowa Percentile Rank (IPR)
- AEA CBM Percentile Ranks
- ICAM Scores
- Class Rank
- Grade and Age Equivalents
- BRI/DRA Scores
- To graph ordinal data, it is best to use Histograms or Line Graphs.
Interval data
Interval data are measured on a scale where each data point has an equal distance from one another; however, there is no absolute zero:
- For the interval scale, intervals by which you are measuring data are all equal in size but there is no absolute zero.
- Interval data can only be added and subtracted.
- Examples include:
- Standard scores (IQ, WJ, Stanford, WIAT, etc.)
- Year (A.D.)
- Fahrenheit
- Celsius
- To graph interval data, it is best to use Histograms or Line Graphs.
Ratio data
Data with equal intervals and includes a true zero is called ratio data:
- Data that is classified as ratio can be added, subtracted, multiplied and divided
- These data points have equal intervals and there is a true zero
- Examples of ratio data include: Iowa Assessment National Standard Score (NSS)
- MAP or RIT Scores
- CBM Raw Scores
- Percent correct
- Frequency and duration raw scores
- When using ratio data, it is best to use Histograms or Line Graphs.
Age/grade equivalents (ordinal data)
Age/Grade equivalent scores indicate that the student has received the same score of an average student of that age or grade. However, it is important to remember that this number does not mean that the individual has the same skills of someone at that grade or age. Age/grade equivalents are often misinterpreted by the average population and are therefore generally not recommended as a good measure to be used when reporting assessment scores.
Example:
If Jessica, a 4th grader, received a 5.4 age/grade equivalent score on a reading probe that means she received the same score an average student who is in the 5th grade in the 4th month would receive when taking the same probe. It does not mean that Jessica has the same skill set as a 5th grader in the 4th month of school.
Resource
| Name | Description |
|---|---|
| What is Disaggregated Data? | A PDF on disaggregated data from the website www.schoolboarddata.org |